Reinforcement Learning Project
Using fNIRS neural data to Improve RL Agent Learning
Highlights
- Project focused on using fNIRS brain data as a physiological input to an RL agent playing pacman.
- The RL agent, which was either a deep Q-network or a dueling deep Q-network, used human demonstrations to help teach itself to play pacman. Human demonstrations are commonly used in this way to improve RL agent learning, but demonstrations where the human makes a mistake can actually be counterproductive. The brain data, therefore, was used as a physiological input to help the RL agent distinguish between good and bad demonstrations.
- The hypothesis was that demonstrations given during times of high mental workload would be more likely to contain mistakes under the assumption that the player may have been overwhelmed at the time. By filtering out these demonstrations, the RL agent should be able to learn faster.
Technologies Used
- Python
- Jupyter notebook
- Tensorflow and tf-agents
- OpenAI Gym
- Deep Q-networks, Dueling Deep Q-networks
Project Introduction & Details
Introduction
Some of the most impressive recent accomplishments in AI have been the result of reinforcement learning (RL) systems. That is, AI systems that learn and adapt to their environment. These systems can perform complex tasks with little-to-no prior information by exploring their environment and developing a behavioral policy as they go. This process allows RL agents to learn very complex behaviors. However, RL agents have a tendency to struggle when they start training as they often have little to no information about their environment. In situations like this it can be helpful to give the RL agent a human demonstration of the task to learn from. Doing so dramatically increases the training speed of RL systems by bypassing much of the randomness of the initial training phase. But not every demonstration is created equal. The usefulness of each demon- stration is dependent, of course, on the person giving the demonstration. If the demonstrator is not paying attention, or is feeling overwhelmed then they are unlikely to provide a useful demonstration to the agent. In which case, it would be beneficial to be able to distinguish between good and bad demonstrations as you could prioritize better demonstrations over worse ones.
One way this could be accomplished is by deciding which demonstration is the best using additional physiological signals from the demonstrator. One potential source of such signals is brain imaging. Brain imaging devices like fMRI or fNIRS shine light through the outer layers of the brain in order to measure the levels of oxygenated blood present in different regions of the brain. These levels of oxygenated blood can then be used to infer information about the current state of the brain. In particular, researchers have gotten quite good at discerning between states of high workload and low workload. So, the question is, is high/ low mental workload a useful feature for deciding which demonstration is the best? The goal of this project was to answer this question by examining the impact of including mental workload as an input to a training RL agent.
Project Diagram
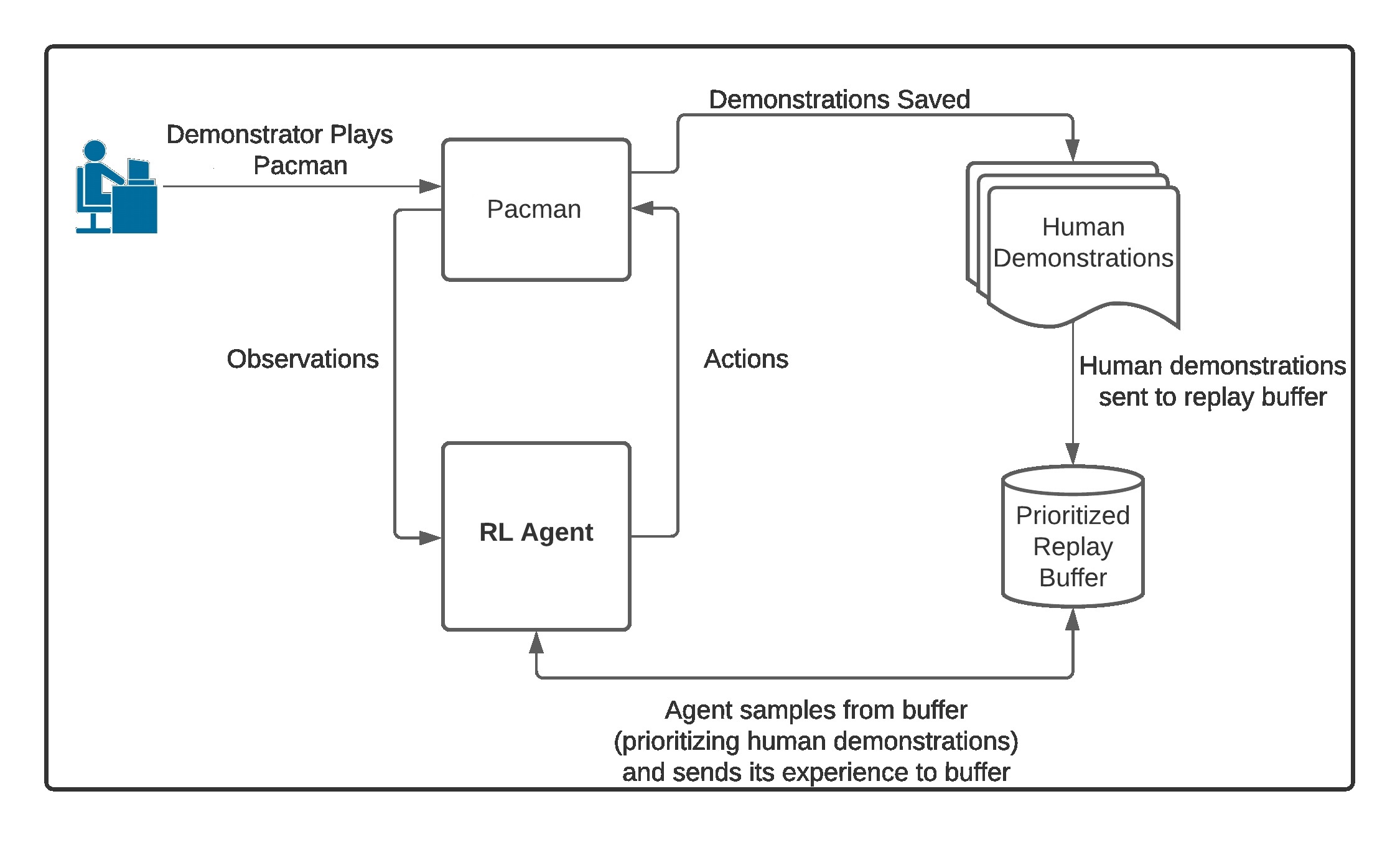
Below, you can view some of the results of this project. These videos show different agents playing Pacman. The first is a random set of actions, the second is me playing (to create demonstrations for the project), and the last is the trained deep Q-netowrk model playing.